HTTP The Definitive Guide - 09. Web Robots
title: HTTP The Definitive Guide - 09. Web Robots
date: 2022-11-30
tags:
- Network
- HTTP
Introduction

GDSC에서 해당 서적을 통해 HTTP를 공부하는 스터디에 참가하고 있다.
HTTP 이전의 내용은 개인적으로 공부하며 채울 예정이다.
이번 Chapter는 09장 Web Robots 이다.
Purpose
Web Robot에 대해 학습한다.
Crawler and Crawling
Web Crawler는 Web Page를 재귀적으로 가져온다.
HTML Hyperlink를 따라 재귀적으로 Crawl 하기에 Crawler 혹은 Spider라고 불린다.
검색 엔진의 경우 Crawler를 이용하여 Document를 가져온 후, 이를 DB에 작성하여 검색하기 쉽게 만든다.
현재 Scraper라는 용어도 존재한다. 특정 목적에 특화된 Crawler의 느낌이다.
Crawling은 전체적인 Web에서 가져오며, Scraper는 특정 Web에서 가져온다고 생각하면 편하다.
Start from Root
Web Page는 너무나도 많으며, 각자 가리키는 Page는 균일 되지 않다.
복잡하게 얽혀 있기에 시작을 잘못 잡으면 Crawling 성능이 좋지 않다. Root Set에서 시작하는 것이 제일 효율적이다.
최근에 만들어지거나 너무 과거의 Page의 경우 가리키는 Page가 없는 고립된 Page들도 존재한다.
Root Set은 www.google.com과 같이 큰 Page, 최근에 만들어지거나 잘 알려지지 않거나 자주 연결되지 않는 Page들로 구성된다.
검색 엔진과 같이 대규모 Production Crawler는 이러한 페이지를 가져오는 방법을 가지고 있다.
Extracting Link and Normalizing Relative Link
Crawler는 HTML Page의 URL을 Parsing하여 Crawling 해야 하는 Page 목록에 추가한다.
상대적인 URL의 경우 Chapter 02에서 배운 방식을 이용하여 절대적인 URL로 바꾼다.
Cycle Avoidance

여러 Page가 가리키는 Page들이 Cycle을 만들 수 있기에 이미 Crawling한 Page를 기록해야 한다.
기록을 하지 않을 경우, 위 그림에서 A - B - C의 Cycle이 반복될 수 있다.
Loop and Dup
Cycle은 단순히 동일한 작업의 반복 문제가 아니다.
Cycle이 발생한다면 같은 Page를 반복해서 Crawling하며, Server의 Network를 차지하여 과한 Bandwidth를 사용하거나 실제 유저가 사용하지 못할 수도 있다.
또한 Loop로 인하여 동일한 Document가 매우 많이 생기며, 이를 Dup이라고 한다.
Crawler 내부에는 쓸모없는 Dup으로 가득해지며, 검색 엔진이라면 같은 Document만 노출하여 사용이 불가능할 수 있다.
Saving Visited URL
방문한 URL을 저장하는 것은 매우 어렵다.
최소 몇십억 개 이상의 URL이 존재하며, 평균적으로 40 Characters를 차지할 때 약 20GB의 공간이 필요하다.
또한 이러한 규모의 Crawler는 검색 엔진일 가능성이 높으며, 빠르게 Crawling하는 것 또한 중요하다.
방문한 URL을 저장하기 위해 여러 방안이 제시되었다.
- Tree & Hash Table - Tree나 Hash Table을 이용한다.
- Lossy Presence Bit Map - Bit Masking이라고 보면 이해하기 쉽다. 상대적으로 작은 공간에 저장하지만, 여러 URL이 하나의 Presence Bit로 충돌할 수도 있기에 주의해야 한다.
- Checkpoint - URL을 Disk에 전부 저장하는 것 같다.
- Partitioning - Web은 점점 많아지기에 단일 Crawler로 처리하기에는 성능이나 가용 가능한 Resource가 부족할 수 있으며, 이 때문에 여러 Crawler를 동시에 이용한다. 각 Crawler에게는 할당된 URL에 대해서 Crawling 한다.
Morgan Kaufmann에서 출판한 Managing Gigabytes: Compressing and Indexing Documents and Image 라는 서적을 추천한다고 한다.
본 서적은 과거에 집필하였기에 추천한 서적 또한 과거의 서적일 것이며, 더 좋은 서적이 최근에 출판되었을 수도 있다.
URL Aliasing

적절한 자료구조를 이용하여 URL을 정리하더라도, URL Aliasing으로 인하여 동일한 Web을 다르다고 인식할 수도 있다.
Canonicalizing URL
URL Aliasing 문제를 해결하기 위해 URL 정규화가 필요하다.
Port가 명시되지 않았으면 80 Port를 붙이며, %xx 방식의 Escape Character를 일반 Character로 바꾼 후, # Tag를 삭제한다.
이 방식을 거치면 이전 URL Aliasing에서 a-c는 해결할 수 있다.
정규화로 해결할 수 없는 d-f와 같은 문제도 존재하며, 약간 다른 방식을 이용하여야 해결할 수 있다.
- d - Crawler가 대소문자를 구분하지 않는지 확인한다.
- e - Server의 Index Page 구성을 확인하여야 한다. (Default Page)
- f - URL이 가리키는 물리적인 컴퓨터의 IP Address와 Hostname을 알고 있더라도, URL이 Virtual Hosting을 하고 있는지 확인해야 한다.
Filesystem Link Cycle
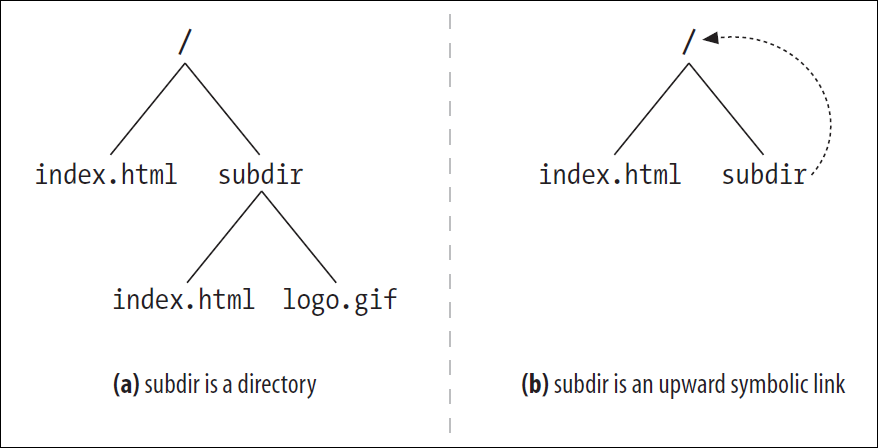
URL이 서로 가리키는 Cycle에 대해 알아보았으나, Filesystem의 문제로 발생하는 Cycle도 존재한다.
위 그림에서 (a)는 subdir가 Directory이기에 문제가 되지 않는다.
(b)는 해당 Directory를 가리키는 Symbolic Link이다.www.foo.com/index.html과 www.foo.com/subdir/index.html 모두 같은 index.html 파일을 가리키나 URL은 다르다.
Crawler가 이를 모른다면 (b)를 가져올 때 영원히 같은 index.html을 가져올 것이기에 이를 막을 방법을 고안해야 한다.
Dynamic Virtual Web Space
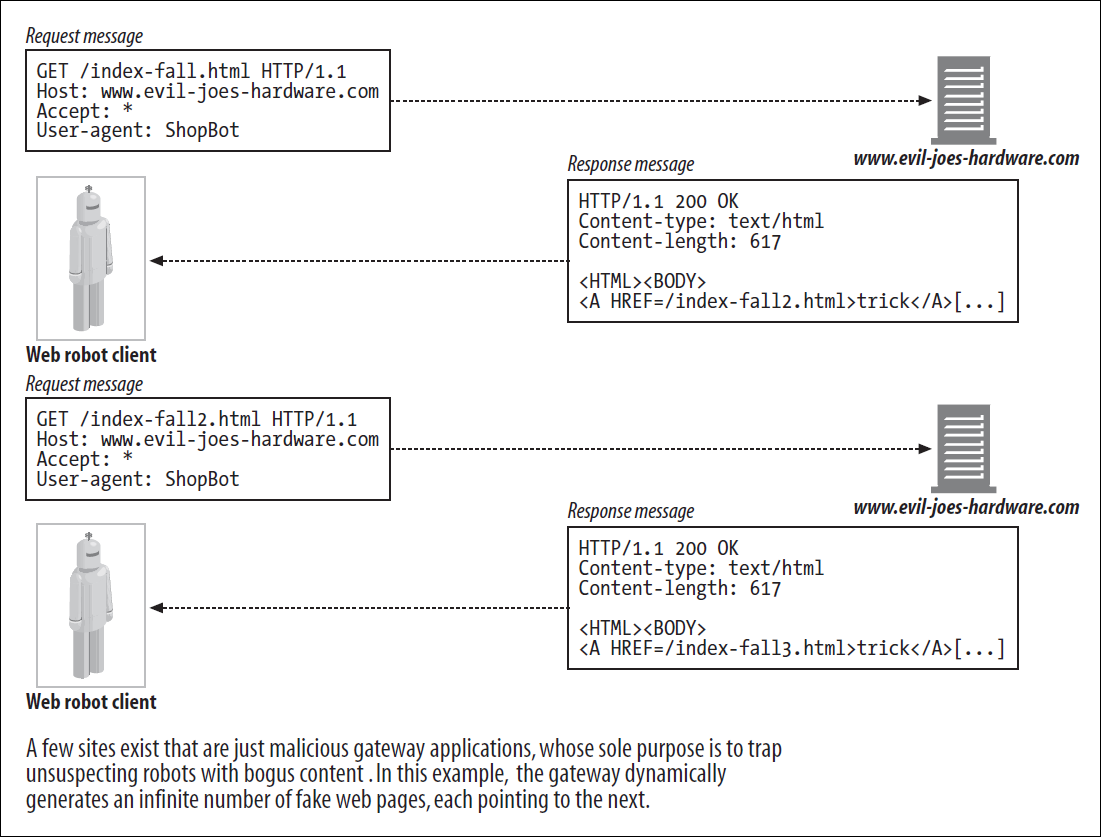
일부 유저가 악의적으로 Web을 구성하여 Crawler의 동작을 방해할 수 있다.
URL을 이용하여 Gateway Application을 Web처럼 보이도록 구성한다.
Symbolic Link나 Dynamic Content를 이용하여 실제 파일이 존재하지 않더라도 파일이 남은 것처럼 보이게 할 수 있다.
교묘하게 바뀌는 URL로 인하여 Crawler는 Cycle에 빠진 것을 눈치채지도 못하고 해당 Web에서 평생 잘못된 Crawling을 진행한다.
악의적인 목적이 없더라도 CGI로 인하여 문제가 발생하기도 하였다.
월별 달력을 가지고 있는 CGI를 Crawling할 때, Crawler는 반복적으로 다음 월을 요청하였다.
이는 실제로 일어난 일이며, 이 때문에 많은 Crawler는 URL에 cgi가 있다면 Crawling하지 않는다.
Avoiding Loop and Dup
Cycle을 피할 완벽한 방법은 존재하지 않는다.
일반적으로 Crawler가 알아서 작동하도록 놔둘 경우 문제가 생긴다.
Crawler가 Cycle을 피할 수 있는 Algorithm을 적용하여 Cycle을 피할 수 있으나, 이로 인하여 일부 Content의 Crawling을 하지 못하는 손실이 발생한다.
- Canonicalizing URL - URL 정규화를 통해 중복 Crawling을 피한다.
- Breadth-First Crawling - BFS 방식으로 Web을 Crawling한다. Cycle을 이루기 전에 수백만 개의 Page를 Crawling할 수 있다. 또한 여러 Server를 이용하기에 하나의 Server를 점유하지 않는다.
- Throttling - 특정 시간 동안 가져올 수 있는 Page의 수를 제한한다. 해당 Chapter의 Robot Etiquette에서도 다룬다.
- Limit URL Size - URL의 길이를 제한하며, 보통 1KB로 설정한다. 일부 Server는 너무 긴 URL을 사용하지 못하며, 이로 인해 Server에 문제가 발생하면 Crawler를 악의적인 공격으로 인식할 수도 있다. 특정 Resource는 매우 긴 URL을 사용하기에 이를 놓칠 수 있으나, Logging을 통해 특정 Web에서 문제가 발생하는 것을 파악할 수 있다.
- URL/Site Blacklist - Cycle이 발생하면 해당 URL을 Blacklist에 등록하여 피한다. 대부분의 방대한 Crawler는 Blacklist를 가지고 있다. 일부 Server는 Crawling을 원하지 않기도 하며, 의도적으로 문제를 발생시켜 Blacklist에 등록되도록 유도한다. 이는 Excluding Robot에서 자세히 다룬다.
- Pattern Detection - Filesystem이나 잘못된 구성으로 인하여 Cycle이 발생할 경우, 보통 Pattern이 존재한다. 이러한 Pattern을 파악하여 Cycle을 피한다.
- Content Fingerprinting - MD5와 같은 방식을 이용하여 Checksum을 계산하여 Crawling 여부를 판단한다. 일부 Server는 동적으로 Resource를 변경하며, 이 경우 날짜나 Access Counter 등을 추가로 제공하기에 중복 탐지를 방지할 수 있다.
- Human Monitoring - 위에 작성한 기법을 이용하여도 Cycle이 발생할 수 있다. Production 환경에서 사용하는 Crawler는 Logging 기능이 있기에 이를 모니터링하여 인간이 직접 처리한다.
방대한 Crawler는 계속하여 Crawling을 진행하고 있으며 발전되고 있다.
하지만 작은 Crawler는 문제가 생기기 쉬워 Human Monitoring이 많이 필요하다.
Robotic HTTP
Crawler는 다른 HTTP Application처럼 동일하게 HTTP Message를 이용한다.
최소한의 HTTP를 이용하며, 초기 구현 이후 거의 바뀌지 않기에 요구사항이 적은 HTTP 1.0을 주로 사용한다.
Crawler에서 필수적으로 사용하는 Header는 매우 적다.
- User-Agent - 어떠한 Crawler가 Request를 하는지 명시한다.
- From - Crawler를 사용하는 유저나 관리자의 이메일이다.
- Accept - 어떠한 타입의 Resource를 사용할 수 있는지 명시한다.
- Referer - Crawler가 해당 URL을 알아낼 수 있었던 Resource의 URL을 알려준다.
Virtual Hosting
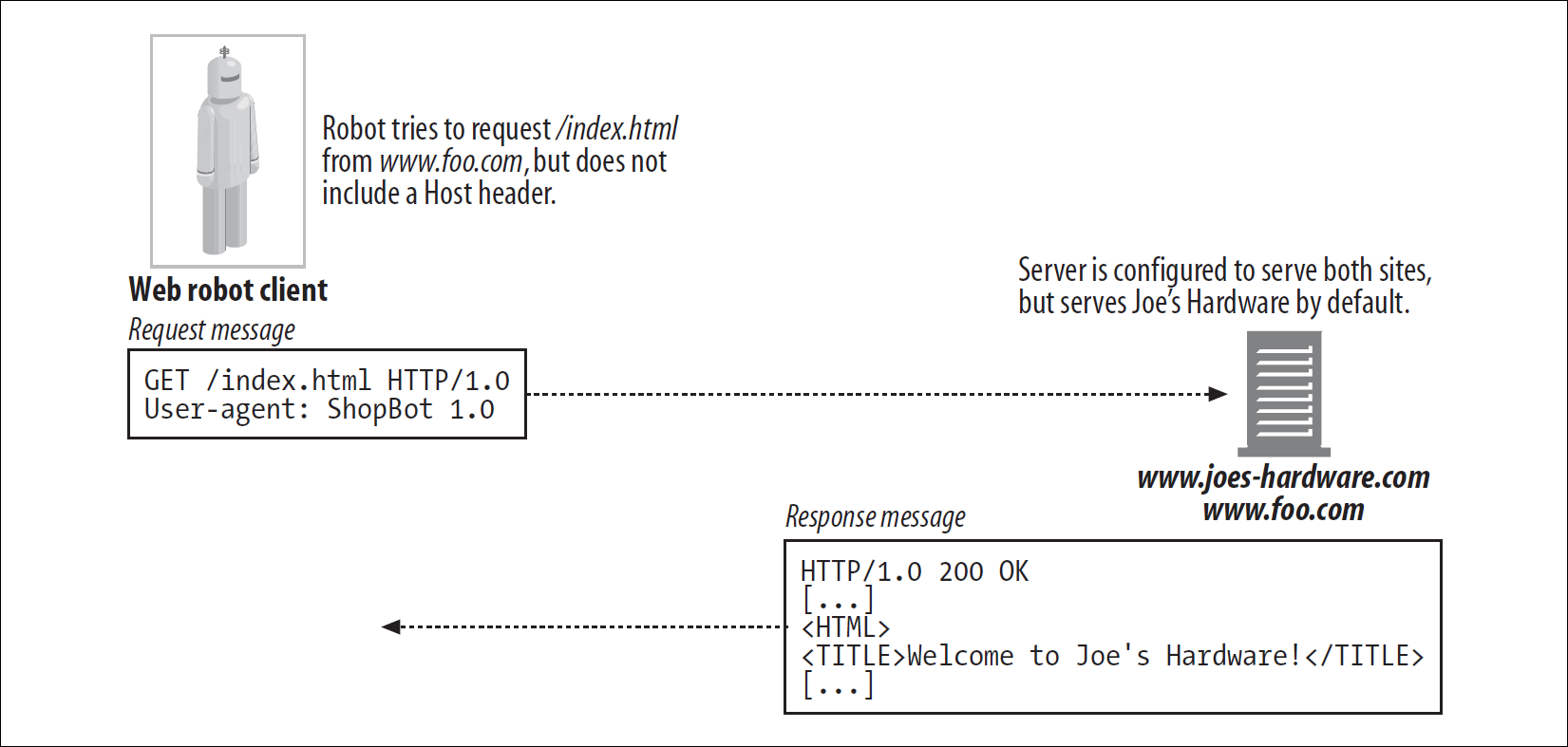
Virtual Hosting이 가능하기에 Crawler에서는 추가로 Host Header를 지원해야 한다.
위 그림에서 Crawler는 www.foo.com의 Resource를 원하지만, Server는 Default인 www.joes-hardware.com을 준다.
Conditional Request
Crawler는 방대한 Web을 Crawling하기에 해당 Web이 바뀌었을 때만 Crawling하는 것이 합리적이다.
일부 Crawler는 Conditional Request를 이용하며, 수정 날짜나 ETag를 통해 Web이 바뀌었는지 알아낸다.
이는 Cache의 Revalidation 작업과 유사하다.
Response Handling
Crawler는 GET Method를 주로 이용하기에 Response Handling이 필요 없을 수 있으나, Conditional Request도 사용하기에 다양한 HTTP Response에 대처할 수 있어야 한다.
- Status Code - 일반적으로 Server의 Status Code 200 OK 혹은 Status Code 404 Not Found를 예상한다. 하지만 Header의 Status Code 200이더라도 Body는 에러를 알려줄 수도 있다.
- Entity - Entity에 Header와 관련된 정보가 포함되기도 한다.
http-equiv와 같은 Meta HTML Tag에는 Resource에 대한 추가 정보가 포함되어있다. 일부 Server에서는 이를 Parsing하여 Header로 넘겨주며, 그렇지 않다면 HTML의 HEAD를 확인하여 이러한 Meta Tag를 이용할 수 있다.
User-Agent Targeting
Web Site를 구현한다면 Crawler가 Request를 보낼 것을 알고 있어야 한다.
많은 Web에서는 User Agent에 최적화하여 Web을 보여주며, 이 경우 Crawler에 Resource 대신 에러를 Response할 수 있다.your browser does not support frames라는 문구로 검색하면 이를 포함하는 에러 Page를 조회할 수 있다고 한다.
Crawler의 Request에 대한 처리를 어떻게 할지 계획해야 한다.
User Agent와 관계없이 동일한 Resource를 Response할 수도 있으며, Crawling을 하지 못하게 처리할 수도 있다. 이는 Excluding Robot에서 자세히 다룬다.
Misbehaving Robot
Crawler를 사용하면서 아래 문제가 생길 수 있다.
- Runaway Robot - Crawler의 Algorithm에 문제가 있거나 Cycle에 빠지면 Server에 과한 부하가 생길 수 있다. 부하가 심하면 유저가 해당 Server를 이용하지 못할 수도 있기에 이러한 일이 발생하지 않도록 설계해야 한다.
- Stale URL - Crawler가 과거에 Server의 URL을 이용한 후, 최근에 해당 Server에 변화가 생긴다면 이용했던 URL을 다시 이용한다. 이 경우 존재하지 않는 Resource에 대한 Crawling이 발생할 수 있으며, Server에는 에러 Log가 무수히 많이 쌓이거나 에러 Page를 제공할 때 생기는 Overhead로 문제가 생길 수 있다.
- Long, wrong URL - Crawler의 Algorithm 문제나 Cycle에 빠질 경우 매우 길고 정상적이지 않은 URL을 이용할 수 있다. 이러한 URL을 해석하는 데에 Server에는 많은 Overhead가 발생하며, 최악의 경우 Server가 뻗을 수도 있다.
- Nosy Robot - 일부 Crawler는 Server의 Private Resource를 Crawling하기도 한다. Web Resource를 관리할 때 까먹고 Private Resource에 대한 Hyperlink를 남기거나, 매우 강한 Crawling이 이루어지면 명시적인 Hyperlink가 없더라도 Resource를 가져올 때 Private Resource를 가져오기도 한다. Server의 Private Resource를 가져오지 않는 Algorithm 작성이 중요하다.
- Dynamic Gateway Access - Crawler는 어떠한 Resource에 접근하는지 모른다. 가끔 Gateway Application의 URL을 가져오기도 하며, 이러한 URL에서 Crawling을 진행하는 것은 많은 Resource를 사용한다.
Excluding Robot
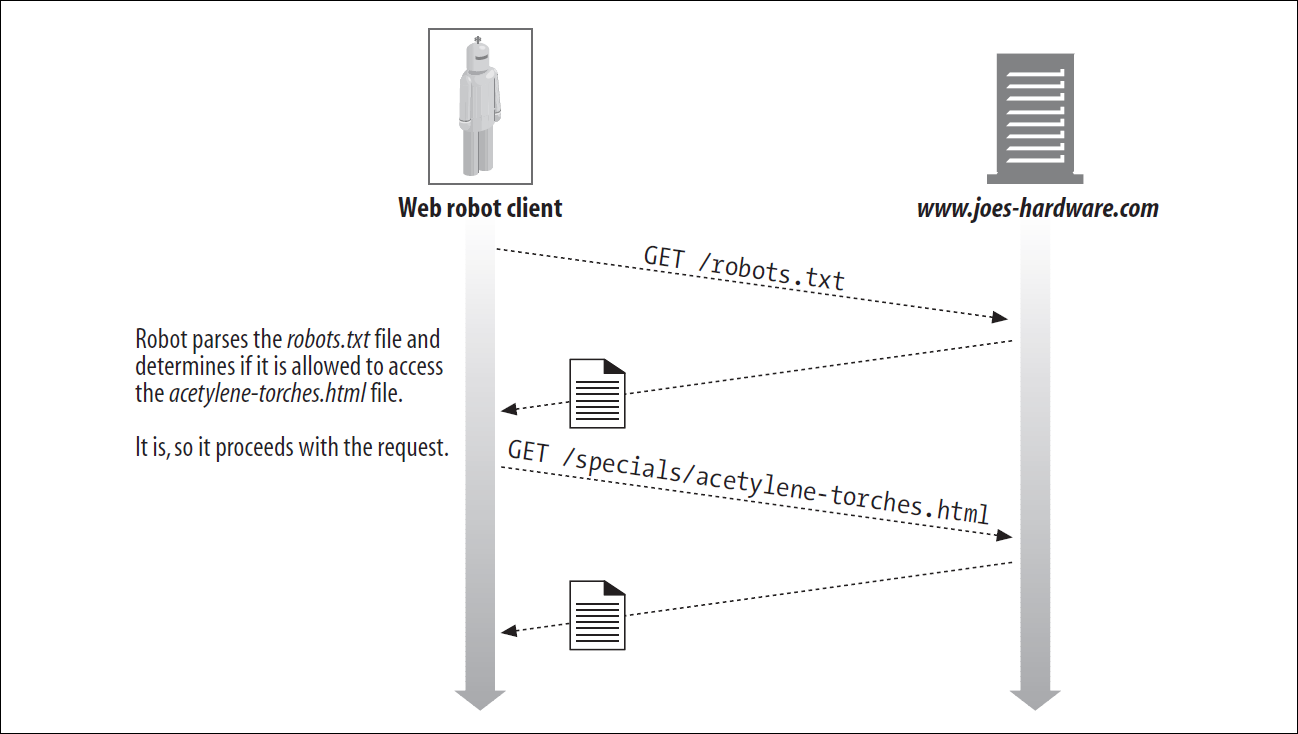
Crawler로 발생하는 문제들을 방지하기 위해 1994년에 Crawler의 동작을 제한할 수 있는 기법이 제안되었다. Robots Exclusion Standard라는 표준이 만들어지고, 이는 robots.txt로 불리게 되었다.
간단히 Server에 robots.txt에 Crawler가 접근할 수 있는 Resource를 작성하는 방법이다. Crawler는 이를 확인한 후, 원하는 Resource에 접근할 수 있을 때 해당 Resource를 가져온다.
Robot Exclusion Standard

Robot Exclusion Standard는 Ad hoc Standard이다.
위와 같이 3개의 Version이 있다고 하나, Google에서 제안한 표준이 최근에 RFC 9309로 게시되었다.
서적 집필 당시에는 Version 0.0과 1.0을 주로 사용하였다. Version 2.0은 훨씬 복잡하여 널리 사용되지는 않았다고 한다.
Version 1.0은 0.0과 호환성이 있기에 본 서적에서는 Version 1.0을 다룬다.
Web Site and robots.txt
각 Web Site에 robots.txt가 항상 존재하는 것은 아니며, 존재한다면 Crawling하기 전 robots.txt를 가져와야 한다.
기본적으로 각 Web Site별 1개의 robots.txt가 존재하나 Virtual Hosting을 한다면 각 Virtual Host별로 robots.txt를 가지고 있을 수 있다.
HTTP GET Method를 이용하여 robots.txt를 확인하며, Server가 Crawler의 정보를 확인할 수 있도록 Request할 때 From과 User-Agent Header를 이용하여야 한다.
robots.txt가 있다면 이를 가져오며 없다면 Status Code 404 Not Found를 받는다.
Status Code 401이나 403의 경우 해당 Web에서 어떠한 Resource도 가져와서는 안 된다.
Status Code 503과 같은 일시적인 에러가 발생하면 다른 응답을 받을 때까지 Resource에 대한 접근을 연기하여야 한다.
Status Code 3xx와 같이 Redirection Response를 받는다면 Resource를 찾을 때까지 Redirection하여야 한다.
robots.txt Format
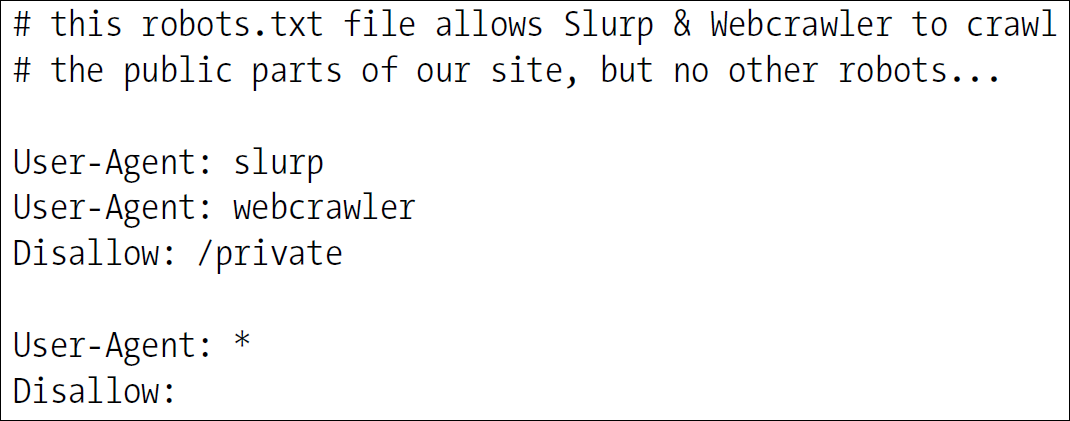
robots.txt의 구성은 간단하다. 주석, 빈 Line, 규칙 세 가지이다. HTTP Header의 형태와 비슷하다.
robots.txt는 Record 단위로 구분된다. 각 Record는 빈 Line, EOF를 기준으로 나눈다.
Comment를 제외한 각 Record는 User-Agent로 시작하며, 이는 어떠한 Crawler에 해당하는 규칙인지 알려준다.
Allow는 허용하는 Resource, Disallow는 허용하지 않는 Resource를 의미한다.
위의 예시에서는 slurp와 webcrawler를 포함하는 Crawler들은 private Directory에 접근할 수 없으며, 다른 Crawler는 모든 Resource에 접근할 수 없음을 의미한다.
User-Agent에 작성된 문자열은 Crawler의 이름에 포함만 되어도 해당하기에 bot과 같이 명시할 경우 Agentbot, Spambot 모두 동일하게 작동하기에 주의해야 한다.

Allow와 Disallow의 경우 대소문자 구분이 존재하며, 접두사 개념이다.
또한 Escape Character를 지원한다. /를 제외한 %XX 방식은 실제 Character로 변환하여 비교한다. /는 Escape Character를 지원하지 않는다.
빈 문자열의 경우 모든 문자열과 매칭된다고 판단한다.
Prefix 방식이기에 특정 경로는 명시할 수 있으나, 특정 이름을 가진 Resource는 명시하려면 모든 Resource를 나열해야만 한다.Private이라는 Resource가 a와 b Directory 안에 있을 경우, /a/Private 과 /b/Private 처럼 모두 나열해야만 한다.
이 외의 Header Extension은 무시한다.
다른 Version과의 호환성을 위해 정의되지 않은 줄 바꿈은 허용되지 않는다.
주석은 파일의 어느 위치에서든 사용 가능하다.
Version 0.0을 사용하는 Crawler는 Allow를 지원하지 않으며, 문제가 발생할 수 있기에 이러한 경우 해당 URL에서 Crawling을 진행하지 않는다.
Caching and Expiration of robots.txt
robots.txt를 다시 가져와야 할 경우, 동일한 Resource를 두 번 가져오는 문제가 생길 수 있다.
Cache처럼 robots.txt의 Expiration Date가 있으며, 파기 날짜가 지나기 전까지 Crawling을 진행하지 않는다.
다만 집필 당시 Production 환경의 Crawler는 HTTP 1.1을 지원하지 않아 Cache와 관련된 Header를 이해하지 못하였다.
Cache 관련 정보가 없다면 7일 동안 Caching이 되지만, 이는 너무 길다.
7일 안에 robots.txt가 갱신되었더라도 Cache가 남아있어 Crawler는 과거의 정보를 이용하여 Crawling을 진행할 것이다.
HTML Robot-Control META Tag
robots.txt는 Web 전체에 적용할 수 있으나, 문서별 설정은 할 수 없다.
HTML META Tag를 이용하면 각 문서별 Robot Exclusion 규칙을 설정할 수 있다.
Robot Exclusion Tag가 존재할 경우, robots.txt를 사용하지 않고 Tag 설정을 따른다.
Robot Exclusion Tag는 아래와 같이 사용한다.
- <META NAME="ROBOTS" CONTENT=`directive-list`>
Robot META Directive
Robot META Directive는 다양하며, 필요에 따라 새로운 Directive가 생성되기도 한다.
서적 집필 당시 주로 사용하던 Directive만 알아본다.
- NOINDEX - 해당 Resource의 Crawling을 금지한다.
- NOFOLLOW - 해당 Resource에 존재하는 Link의 Crawling을 금지한다.
- INDEX - 해당 Resource의 Crawling을 허용한다.
- FOLLOW - 해당 Resource에 존재하는 Link의 Crawling을 허용한다.
- NOARCHIVE - 해당 Resource의 사본을 Caching하는 것을 금지한다.
- ALL - INDEX, FOLLOW를 동시에 이용하는 것과 동일하다.
- NONE - NOINDEX, NOFOLLOW를 동시에 이용하는 것과 동일하다.
META NAME인 robots는 대소문자를 신경 쓰지 않는다.
또한 동일한 Directive를 중복하여 작성하면 문제가 생길 수 있다.
Search Engine META Tag
앞에서 META NAME이 robots인 META Tag에 대해서 알아보았다.
다른 META NAME을 가지는 META Tag들도 존재한다.
- DESCRIPTION - Resource를 요약하여 작성할 수 있도록 한다.
- KEYWORDS - Keyword를 이용한 검색을 할 때, KEYWORD를 직접 정의하여 검색에 용이하게 한다.
- REVISIT-AFTER - 해당 Resource가 변경될 가능성이 높기에 지정한 기간이 지나면 다시 Page를 확인해야 함을 의미한다.
Robot Etiquette
1993년에 Web Robot Community를 설립한 Martijn Koster는 Crawler Guideline을 작성하였다.
시간은 많이 지났으나 여전히 유용하며, 이를 기반으로 Crawler 개발자와 관리자를 위한 최신 Guideline을 알아본다.
WWW Crawler를 대상으로 하는 Guideline이나, 작은 규모의 Crawler에도 적용 가능하다.
- Identification - Crawler와 이를 이용하는 관리자에 대한 정보를 명시한다.
- Operation - 거대한 Web을 Crawling할 때는 미리 알리며, 문제가 생길 경우 조치를 위한 알람 기능을 구현한다. Logging 및 Monitoring을 통해 Crawler의 동작을 확인하여 개선한다.
- Limit Yourself - 이상한 URL이나 Dynamic URL은 처리하지 않는 것이 좋다. Accept Header와 robots.txt을 이용하여 특정 Resource만 Crawling한다. 또한 동일한 Web에 대한 Crawling 간격이 짧다면 Crawling 제한이 생길 수 있기에 적당한 시간 간격을 두어 Crawling한다.
- Tolerate Loop and Dup and Other Problem - 어떠한 Response를 받을지 모르기에 모든 Status Code에 대한 동작을 준비하고 이에 대한 Log를 남기는 것이 좋다. URL 정규화를 통해 Loop 발생 가능성을 줄인다. Monitoring을 통해 악의적인 Loop를 피하며, Blacklist 관리를 통해 이러한 정보를 축적한다.
- Scalability - Crawler 유지에 들어가는 Computing Resource와 Network의 Bandwidth, Crawling에 걸리는 시간 등을 파악하여 Crawler를 최적화한다.
- Reliability - Crawler를 이용하기 전에 내부 테스트를 통해 성능을 확인한다. Crawler에 문제가 생길 경우를 대비하여 Snapshot 등을 준비하여 Crawler를 다시 시작하더라도 중간부터 진행할 수 있도록 한다.
- Public Relation - Crawler의 동작에 불만을 가지는 Web 관리자들이 존재할 것이다. 불만이 접수되면 빠르게 응답하며, Robot Exclusion Standard를 알려주어 불만을 다소 해소할 수 있다. 이럼에도 불만을 가지는 Web 관리자가 남는다면 Blacklist에 추가하여 무시하는 것도 좋다.
Search Engine
Crawler는 검색 엔진에서 주로 사용한다. 유저들은 검색 엔진을 이용하여 원하는 정보를 찾는다.
이 때문에 검색 엔진 중 매우 유명한 Web이 많이 존재하며, 유저들이 Internet을 이용하는 시작 페이지로 동작하는 경우가 많다.
초기의 검색 엔진은 간단한 DB의 형태였으나, 현재는 수십억 개의 Page에 접근 가능하여 필요한 정보를 찾는 데에 필수가 되었다.
수십억 개의 Page와 최소 수백만의 유저가 이용하기에 이를 감당할 수 있어야 한다.
각 HTTP Request에 대한 Response에 0.5초가 소요되고 병렬 처리가 되지 않는다고 할 때, 10억 개의 Page를 조회할 때 약 5700일이 걸린다.
병렬 처리는 필수적이며, 이를 감당하기 위해 많은 Computing Resource가 필요할 것이다.
이러한 상황에서 Crawler를 추가로 운용하는 것도 어려운 작업이다.
Modern Search Engine Architecture

현대의 검색 엔진은 Full-Text Index라는 Local DB를 사용한다. Page가 어떠한 것을 포함하는지를 통해 Keyword가 아닌 Resource의 일부와 매칭하여 더 정교한 검색 결과를 제공한다.
Crawler가 수집한 Resource를 Full-Text Index에 저장하며, 유저는 Google과 같은 검색 엔진을 이용하여 원하는 정보를 찾는다.
Web은 언제나 변하며 Crawling 완료까지 시간이 걸리기에 Full-Text Index는 Web의 Snapshot이라고 볼 수 있다.
Full-Text Index

Full-Text Index는 위 그림과 같은 형태이다.
각 Resource는 추가되는 즉시 검색할 수 있으며, 기본적으로 완전한 단어를 이용하여 검색을 한다.
Posting the Query

HTTP Get Method나 POST Method를 이용하여 검색한다.
검색할 단어, 문장 등을 입력한 후 검색하면 Browser가 해당 내용을 이용하여 HTTP Request를 하며, Server Gateway는 이를 확인한 후 적절한 Resource를 Response한다.
Sorting and Presenting the Result
HTTP Response를 바탕으로 검색 결과를 보여준다.
Relevancy Ranking이라는 방식으로 정렬하며, 검색 결과에 대한 순위를 매겨 이에 맞추어 정렬하는 방식이다.
단순히 검색한 단어, 문장과 많이 매칭되는 Resource를 이용할 수도 있으며, 많은 유저들이 방문한 Page의 우선순위를 높이거나 각 Page에 대한 Weight를 부여하기도 한다.
이에 대한 Algorithm은 검색 엔진의 핵심이라고 할 수 있기에 내부자가 아닌 이상 알아내기는 매우 어렵다.
Spoofing
첫 검색 화면에서 원하는 결과가 나오는 것이 중요하다.
이 때문에 유저가 원하는 것을 예측하여 최상단부터 배치하며, 이때 광고를 받아 특정 Page를 상단에 노출하기도 한다.
상업적 목적의 Web일 경우 더 많이 노출되는 것이 중요하기에 더 많은 Keyword를 나열하거나 가짜 Page를 만들어 노출하기도 한다.
유저가 원하는 결과를 제공하기 위해서는 이러한 Page를 덜 노출해야 하며, Spoofing을 잡아내기 위한 Algorithm을 지속적으로 개선해야 한다.
Conclusion
Crawler를 단순히 특정 Web을 Crawling하는 데에만 이용하였으나 생각보다 훨씬 방대하였다.
검색 엔진과 관련된 Service를 구현하지 않는 한 이러한 방대한 Crawler는 사용할 일이 적을 것이다.
다만 이러한 Crawler가 존재하기에 Web을 구현할 때 예상하지 못한 Crawler에 대한 Traffic이 발생할 수 있음을 알고 있어야 할 것이다.