Machine Learning Engineering for Production (MLOps) - C1 W1
title: Machine Learning Engineering for Production (MLOps) - C1 W1
date: 2022-11-02
tags:
- MLOps
Introduction
GDSC AI/ML에서 진행하는 스터디로, MLOps 강의를 듣고 이에 대해 함께 공부한다.
이번 강의는 Chapter 1 Introduction to Machine Learning in Production의 Week 1 Overview of the ML Lifecycle and Deployment이다.
Purpose
ML Lifecycle과 Deployment에 대해 파악한다.
The Machine Learning Project Lifecycle
Welcome
스마트폰 생산 공정을 예시로 ML 환경에 대해 설명하던 중, Drift라는 키워드가 나온다.Drift는 Model의 성능이 시간이 지남에 따라 감소하는 것이며, 여러 Drift가 존재한다.
간단히 Data Drift는 Input Data가 학습과 다르게 주어지는 것을 의미한다. 위 예시에서는 동일한 액정의 손상이더라도 빛의 세기에 따라 이를 인식하지 못하는 상황이었다.
이와 비슷하게 Concept Drift가 존재한다. 이는 예측하려는 정답에 대한 기준이 현실에서 바뀌었기에 생기는 문제이다. 이전에는 특정 위치의 손상도 액정 손상이라고 판단하였더라도, 정책의 변화로 해당 위치의 손상은 정상으로 판단하도록 바뀌어도 Model은 여전히 이를 손상이라고 판단하게 된다.Lable Drift와 Prediction Drift라는 개념을 추가로 알게 되었다. Label Drift는 Target Shift라고도 불리며, 정답의 기준이 바뀐 것이라고 보면 된다. Prediction Drift는 예측값의 변화로 인하여 데이터와 예측값의 관계에 변화가 생긴 것이다. 이것은 Concept Drift의 전조 증상일 수 있다.POC라는 개념도 등장한다. 이는 Proof of Concept로, 프로젝트가 실제로 효과가 있는지에 대해 검증을 하는 것이다.
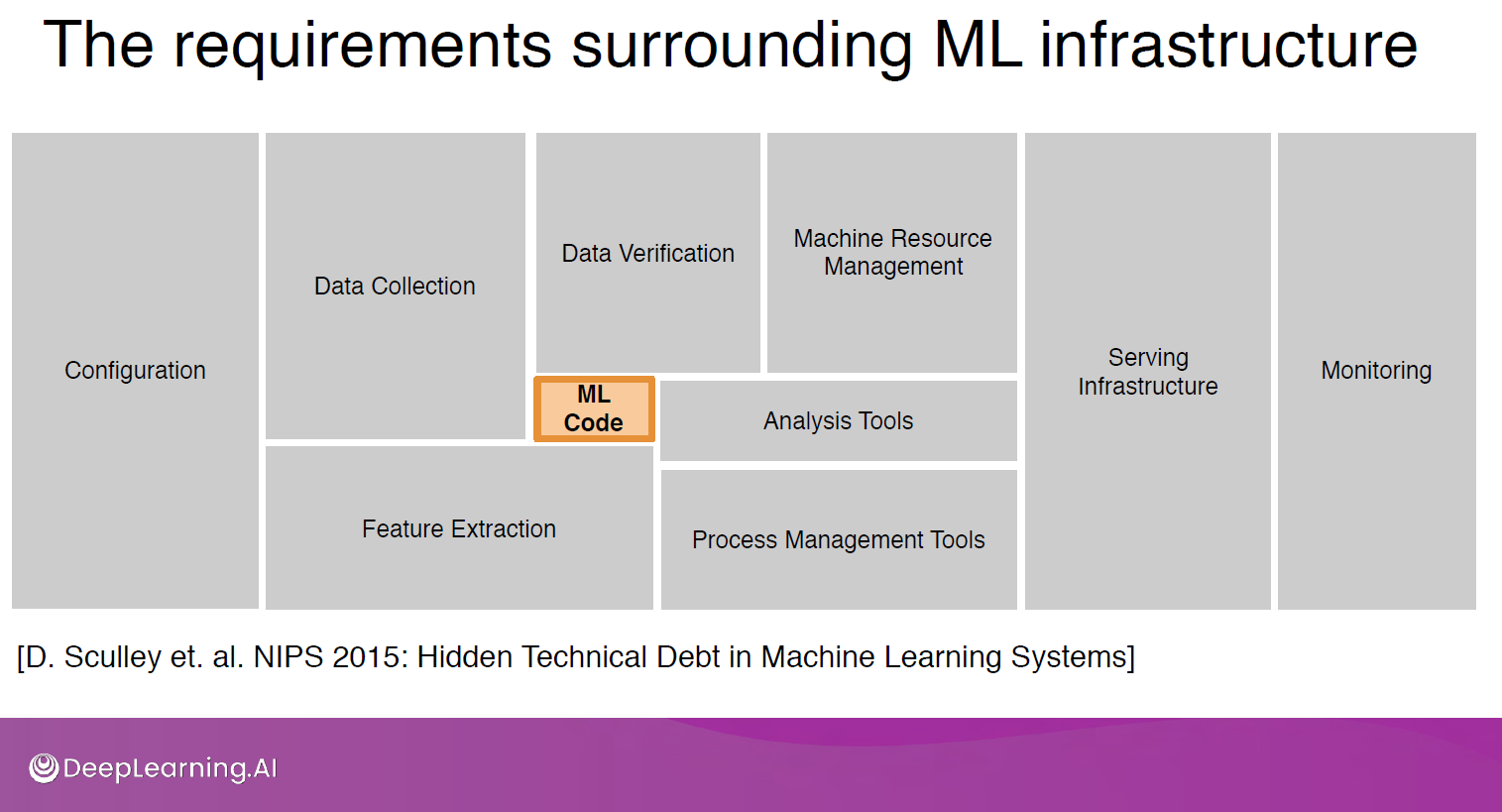
ML 자체에 대한 코드는 5~10%, 혹은 이보다 적다. 이 외의 부분은 ML을 사용하기 위해 준비하는 단계부터 이를 서빙하고 모니터링하는 과정이 차지한다.
Step of an ML Project
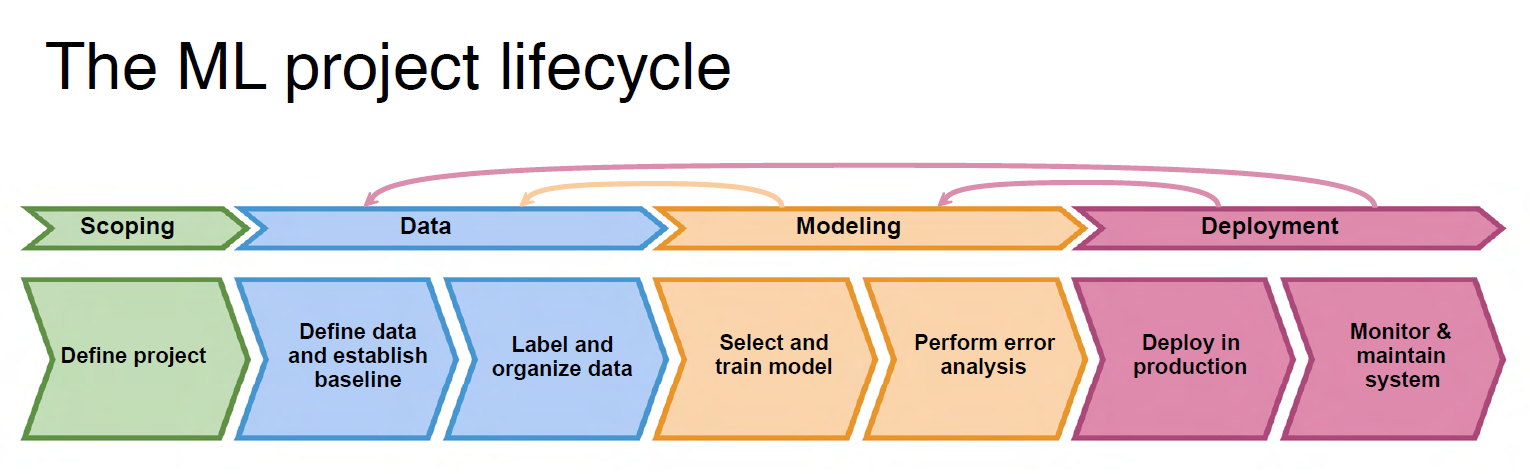
ML Lifecycle은 ML 프로젝트에 대한 단계를 보여주는 것이라고 봐도 된다.
처음에는 Scoping으로, 문제를 규정하고 X -> y에서 X와 y가 무엇인지 정의하는 등에 대한 것이다.
두 번째는 Data로 데이터 수집 및 라벨링까지 진행한다.
Modeling은 Model을 이용하는 부분이다. 학습을 통해 결과를 얻어내며, 결과에 문제가 있는지 분석하여 다시 학습을 하거나 데이터를 더 모으거나 라벨링 하는 과정으로 돌아간다.
의미 있는 결과를 통해 서비스에 기여가 가능할 때 Deploy를 진행한다. Deploy 환경을 구축한 이후에는 이를 모니터링하여 시스템이 잘 돌아갈 수 있도록 한다. 문제 혹은 X가 바뀌거나, 학습을 다시 진행해야 할 수도 있다. 이러한 과정을 통해 지속적으로 Model을 관리하는 것이다.
Case study: speech recognition
음성 인식 프로젝트를 예시로 ML Lifecycle에 대해 더 알아본다.
Scoping에서 규정하는 문제는 음성 인식을 이용한 검색이다. 문제에 있어서 음성 인식에 대한 정확성, 말하기가 완료되고 검색이 되기까지의 지연 시간, 초당 최대 처리 가능한 횟수 등에 대한 부분을 고민하고 해결해야 한다.
추가적으로 가능하다면 이를 위해 필요한 Resource에 대해 예측하는 것이 좋다.
Scoping에 대한 더 자세한 내용은 Week 3에서 다룬다.
데이터를 수집하는 것은 크게 문제가 되지 않는다. 유저는 검색을 위해 음성을 말하는 것이므로, 이를 이용하면 된다.
문제는 Labeling이다. 강의에서는 추임새로 예측되는 문구가 함께 녹음되었을 때, 이를 어떻게 처리하냐에 대해 설명하였다. 여러 경우의 수가 존재하겠으나, 비슷한 문제는 매우 많이 존재할 것이기에 이러한 측면에서 Labeling에 대한 명확한 기준을 정하고 이에 맞추어 Labeling을 진행해야 적어도 나쁜 성능은 피할 수 있다.
또한 음성의 앞뒤에 존재하는 공백의 시간, 볼륨에 대한 측면도 언급을 하였다. DAW를 이용한 작곡을 할 때, 볼륨을 측정해주는 VST가 존재한다. 음성만 존재하면 볼륨을 맞추기 쉬운 편이지만, 잡음이 섞일 경우는 매우 어려워진다.
결국 이러한 고민들은 데이터의 정확성에 대한 고민이라고 볼 수 있는 것이다.
실제 production에 있어서 많은 데이터에 이러한 작업을 하는 것보다는, 이것을 반영하여 적절한 학습 데이터를 이용하여 학습을 하는 것이 좋을 수도 있다.
Modeling에 있어서 Model에 대한 알고리즘을 반영한 코드, 하이퍼파라미터, 데이터를 이용하여 학습을 진행한다.
학문적으로 접근할 때는 데이터를 고정하고 나머지 2가지를 변경하는 반면, 실제 product에서는 Code를 고정하고 나머지 2가지를 변경하는편이다.
물론 Code를 수정하여 성능을 높일 수도 있으나, 보통 좋은 오픈소스를 이용하여 Code를 고정하되 데이터에 대한 최적화를 진행한다.
Model의 결과가 옳은지에 대해 분석하고, 이를 이용하여 데이터를 발전시키는 시스템을 구축한다면 더 좋은 성능을 얻을 수 있다.
또한 일반적으로 많은 데이터에 집중하는데, 데이터는 늘 꾸준히 들어온다. 그렇기에 결과 분석을 통해 어떠한 데이터가 유입되는지 파악한다면 성능을 더 높일 수 있다.
Deploy 단계에서는 실제 사용할 수 있는 서비스를 구축한다. 모바일 환경이라고 가정할 경우, App에서 VAD (Voice Activity Detection) Module을 이용하여 음성 인식을 한 후, 이를 Cloud에 존재하는 서비스에 보낸다. 강의에서는 이를 Model Server처럼 표현하였으나, 실제 서비스라면 Model Server에 직접 보내기 전에 이를 관리하는 Server가 존재할 것이다. 예측 결과와 검색 결과를 App으로 다시 보내주고, App에서는 이를 화면에 띄워주면 된다.
이와 같이 구축이 완료되면 모니터링을 통해 서비스를 이어 나가면 된다. 이 때 처음에 언급한 Data Drift나 Concept Drift가 발생할 수 있으며, 이를 적절하게 대처하면 좋은 서비스를 이어 나갈 수 있다.
Deployment
Deploy에는 크게 두 가지의 문제가 있다. ML과 통계학적 문제, 그리고 SW Engine 문제이다.
이전에 예시를 든 음성 인식을 이용하여 더 자세하게 알아본다.
Key challenges
학습을 완료한 Model을 이용하여 서비스를 Release한 상황이다. 하지만 인간들이 주로 사용하는 단어, 혹은 스마트폰 성능의 변화로 인하여 Model의 성능은 감소할 가능성이 있다.
이 때 Gradual Change와 Sudden Change가 존재한다. Gradual Change는 새로운 단어를 이용하는 등 매우 느린 변화이다. Sudden Change는 말 그대로 급격한 변화이다. 코로나 이후 인간들의 소비는 오프라인에서 온라인으로 급격하게 옮겨갔으며, 카드사는 이로 인해 변화된 데이터에 맞추어 Model을 재학습시켜 이용하였다.
Concept Drift와 Data Drift에 대한 설명도 더 많은 예시를 통해 진행하였다. 간단히 주택을 통해 가격을 예측할 때, 동일한 주택이라도 가격이 변화하면(y 변화) Concept Drift, 주택이 변화하는 경우(X 변화) Data Drift이다.
지금까지 살펴본 것이 ML과 통계학적 문제이다.
Model의 처리 시간에 따라 Real Time과 Batch로 나눌 수 있다. 음성 인식을 이용한 검색이라면 즉각적으로 반응해야 하기에 Real Time이지만, 환자들에 대한 기록을 남기기 위해 녹음한 후 Batch 형태로 처리할 수 있다.
또한 현재는 클라우드 컴퓨팅이 많이 사용되나, 자동차 혹은 와이파이가 없어도 작동해야 하는 시스템이라면 클라우드가 아닌 해당 기기에 Model을 탑재해야 할 것이다. 공장에서 사용하는 일부 Model은 인터넷의 연결에 관계없이 항상 작동해야 하기에 클라우드 대신 자체 기기에 탑재하는 경우도 존재한다.
언제나 최고 성능을 보장하면 좋겠지만 Resource는 한정되어있다. CPU, GPU, Memory는 한정적이며 예측 결과를 알려주는 시간에 따라서도 요구치가 달라질 것이다.
Latency와 QPS (Query Per Second)도 중요하다. Real Time 서비스라면 많은 유저들이 동시에 사용할 수 있으며, 이때 즉각적으로 서비스가 이루어지지 않는다면 문제가 생길 수 있다.
Latency Bound를 설정하여 해당 시간 이내로 서비스가 이루어져야 하며, 많은 요청이 동시에 들어와도 적절하게 처리할 수 있어야 한다.
Logging은 놓치기 쉬우나 이 또한 하나의 데이터라고 볼 수 있다.
수집되는 데이터가 얼마나 민감한지에 따라 보안과 정책을 설정하고, 이에 맞게 디자인해야 한다.
Deployment patterns
Deploy도 프로젝트에 따라 다르게 진행해야 할 것이다.
유사한 서비스조차 존재하지 않는 새로운 서비스의 경우, 작은 트래픽부터 점점 키워나가는 방향으로 진행한다.
기존에 진행되던 무언가를 위해 Model을 도입할 경우, Shadow Deployment가 좋을 것이다.
마지막으로 기존에 사용하던 Model을 교체할 경우, 아예 엎어버리는 것이 더 좋을 것이다. 새로운 Model에 적은 양의 데이터를 이용하여 학습할 수도 있으며, 새로운 Model의 성능이 좋지 않다면 이전에 사용하던 Model로 돌아갈 수도 있다.
Shadow Deployment는 의사 결정에 기여하지는 않지만 기존 의사 결정 구조를 이용하여 검증하는 절차라고 볼 수 있다. 인간 혹은 Model의 판단과 비교하여 새로운 Model에 문제가 있는지 확인할 수 있으며, 신뢰성이 보장되면 그때 새로운 Model을 의사 결정하는 데에 이용할 수 있다.
Canary Deployment는 Model의 최종 검증이라고 볼 수 있다. 실제 환경에서의 동작을 확인하고, 문제가 있다면 이를 개선하여 다시 검증할 수 있으며, 문제가 없다면 실제 환경에서 사용할 수 있다.
Blue Green Deployment는 Release시 Rollback이 필요한 수준의 문제가 발생하여도 대처가 가능하다. 기존 시스템을 Blue Version, 새로운 시스템을 Green Version이라고 한다. Blue Version에 보내어 처리하다가 Green Version으로 보내면 순식간에 시스템 변경이 되는 것이다. Green Version에 문제가 생겨서 Rollback을 해야 한다면 다시 Blue Version으로 보내면 된다. 물론 모든 데이터를 Green Version으로 전환하지 않고, 적은 양에서 점점 많은 양으로 늘리는 경우도 존재한다.

Automation은 크게 5단계로 분류된다. Human Only(인간만 존재) - Shadow Mode(인간의 결정을 학습) - AI Assistance(더 쉬운 의사 결정을 위한 AI의 Assist) - Partial Automation(AI가 확신하지 못하는 경우만 인간이 처리) - Full Automation(전체 AI 처리)
늘 Full Automation을 목표로 하지 않아도 된다. AI Assistance나 Partial Automaiton에서 멈춰도 되며, 이 두 단계에서 Loop Deployment를 적용하는 것이 Full Automation보다 좋을 수 있다.
Monitoring
다양한 지표들을 Monitoring해야 큰 문제가 발생하기 전에 이를 파악하고 해결할 수 있다. 처음 서비스를 시작할 때 가능한 모든 지표를 모니터링하는 시스템을 구축한 후, 사용하지 않는 지표들에 대해서 제거하는 방법도 괜찮다.
- SW Metrics : Mem, Compute, Latency, Throughput, Server Load
- Input Metrics : X의 범위나 데이터 자체가 바뀔 때 이를 확인할 수 있는 지표 등
- Output Metrics : null, y 사용을 포기하고 인간이나 기계가 직접 담당하기로 변경하는 것 등(ML에 대한 신뢰성 저하, 지연 등의 이유)
ML Lifecycle은 Iterative하게 반복된다. Deployment도 동일하다. Deployment/Monitoring -> Traffic -> Performance Analysis 의 반복이다.
Monitoring하는 지표들에 적절한 기준을 잡아 해당 기준을 넘어설 경우 알람이 오도록 설정하여 문제가 생기는 것을 조기에 방지할 수 있다.
Model의 성능을 위해 재학습을 할 경우, Manual Retraining과 Automatic Retraining이 존재한다. 전자는 현재 일반적으로 많이 사용하는 방식이며, 후자는 인터넷을 사용하는 등 일부 케이스에서 사용하고 있다.
Pipeline monitoring
이전까지 확인한 Monitoring은 ML과 관련이 깊은 부분이었다. 하지만 실제 프로젝트에서 ML 코드는 매우 적은 양이기에 ML 외적인 부분에서도 Monitoring을 진행해야 한다.
음성 인식의 경우 Input Metrics의 변화가 사실 VAD Module의 변화가 원인일 수 있다. 스마트폰이 변화하면서 잡음 제거, 앞뒤 공백의 길이, 녹음된 소리의 볼륨 등이 변할 수 있으며, 이는 결국 Input Metrics의 변화이다.
SW Metrics는 ML 외적인 부분을 전반적으로 파악할 수 있도록 해준다.
3가지의 지표가 변하는 속도도 생각해야 한다. 유저의 데이터는 일반적으로는 매우 천천히 변화하지만, B2B 서비스의 경우 기업에 관련된 데이터는 변화가 빠르다.
Conclusion
ML Lifecycle에 대해 개념을 잡았으며, 마지막 단계인 Deploy에 대해 자세히 알아보았다.
일반적으로 데이터의 수집을 시작으로 데이터 웨어하우스 혹은 데이터 마트에 적재하는 것이 데이터 엔지니어의 업무 중 하나라고 알고 있다.
MLOps에서는 이러한 과정이 생략되었으나 데이터 수집도 담당하는 것처럼 되어있으며, 두 포지션이 같은 팀에 존재한다면 업무 분담이 어떻게 되는지가 궁금하다.