title: CSAPP - The Memory Hierarchy
date: 2022-08-10
tags:
- CSAPP
Introduction

학교 개발자 커뮤니티에서 진행하는 CSAPP 두 번째 스터디 내용이다.CSAPP의 일부 챕터만 진행하며, 이번 챕터는 6장 The Memory Hierarchy 이다.
Purpose
Memory Hierarchy에 대한 이해와 이를 활용해야 하는 이유를 배운다.
Memory

현대의 Memory Hierarchy는 위와 같이 나눌 수 있다.
피라미드의 상단으로 갈수록 용량이 작고 Byte당 비용이 크지만 속도가 빠르고, 하단으로 갈수록 용량이 커지고 Byte당 비용이 작아지지만 속도가 느리다.
인접한 두 Layer에서, 상단 레이어는 하단 레이어의 Cache처럼 작동한다.
최하단의 두 Secondary Storage를 묶는 경우도 있으나, 클라우드 환경이 매우 많이 쓰이는 현재에는 나누는 것이 적절하다고 판단하였다.Disk I/O와 Network I/O의 경우 10년 전에는 Network I/O가 더 빨라질 것으로 보였다.
클라우드 기술이 대중적으로 사용되며 클라우드와 Local Disk의 속도 측면에서 의문이 생겨 질문을 올렸으며, 답은 생각보다 간단하였다.
유저가 사용하는 클라우드는 Network만 존재한다고 볼 수 있으나, 이 클라우드는 현실의 어딘가에 물리적인 형태로 존재한다.
결국 이 위치에서 데이터를 가져오고, 이를 Network를 통해 사용한다면 Disk I/O와 Network I/O가 모두 일어나므로 일반적으로 Local Disk가 클라우드보다 빠르다고 볼 수 있다.
RAM
RAM이란 Random Access Memory의 약자로, 원하는 위치에 임의로 접근하여 사용 가능한 공간이다.RAM은 크게 SRAM (Static RAM)과 DRAM (Dynamic RAM) 으로 나눌 수 있다.SRAM은 전력이 공급되는 한 내용을 유지하기에 안정적이다. 상대적으로 빠르며, Density (집적도)가 낮기에 비용이 상대적으로 비싸다.DRAM은 전력이 공급되더라도 주기적으로 refresh를 해주어야 한다. 상대적으로 느리며, Density가 높아 비용이 상대적으로 싸다.
이 외에도 FPM DRAM, EDO DRAM, SDRAM, DDR SDRAM, VRAM 등이 존재한다. 이 RAM들은 서적에서 언급하였다.
서적에서 언급하지 않은 RAM도 많이 존재하기에 심심할 때 찾아보는 것도 좋을 것 같다.
Drive
흔히 사용하는 Local Storage는 HDD (Hard Disk Drive) 이다.
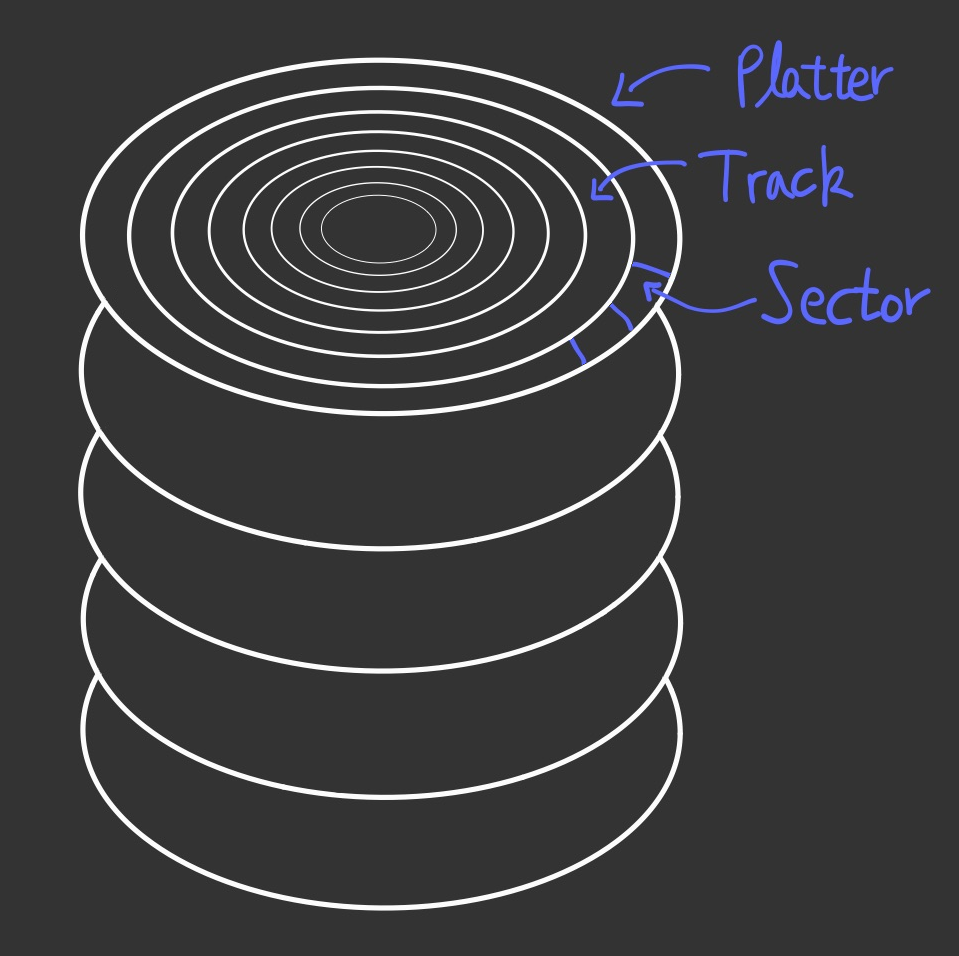
HDD는 데이터가 저장되는 Platter들이 여러장 겹친 형태로 되어 있다. 각 Platter는 여러 Track이 동심원으로 이루어져 있으며, 각 Track은 최소 단위인 Sector로 이루어져 있다.Sector를 연달아 모아서 Cluster를 구성하기도 하지만, 일반적인 데이터 저장 단위는 Sector이다.
한 Sector의 크기가 512Bytes일 때, 1Byte 데이터를 저장하더라도 한 Sector를 전부 쓰게 되고 남은 511Bytes는 해당 데이터가 바뀌지 않는 한 빈 공간으로 놔두고 사용하지 않는다. 이것이 Internal Fragmentation이다.
1GB의 데이터를 저장하려고 할 때, 연속되는 1GB 공간이 없다면 데이터를 저장할 수 없는 경우 External Framentation이라고 한다.
최근에는 물리적으로 데이터를 저장하는 HDD와 다르게 전기적인 신호를 통해 데이터를 저장한다.
비휘발성 저장장치이기에 데이터가 영구적으로 저장된다고 생각할 수 있으나, SSD는 오랫동안 전력 공급이 되지 않을 경우 데이터가 유실될 수 있다. 이는 SSD가 Flash Memory의 일부이기에 가지는 특징이다.HDD는 데이터가 물리적으로 저장되기에 이를 찾는 시간으로 인하여 속도가 상대적으로 느리나, SSD는 전기적 신호를 이용하기에 HDD보다는 매우 빠르며, RAM 보다는 느리다.
Cache
이전에 Memory Hierarchy의 인접한 레이어 중 상단 레이어가 하단 레이어의 Cache처럼 작동한다고 하였는데, 이에 대해 알아보기 위해 Cache에 대해 알아야 한다.
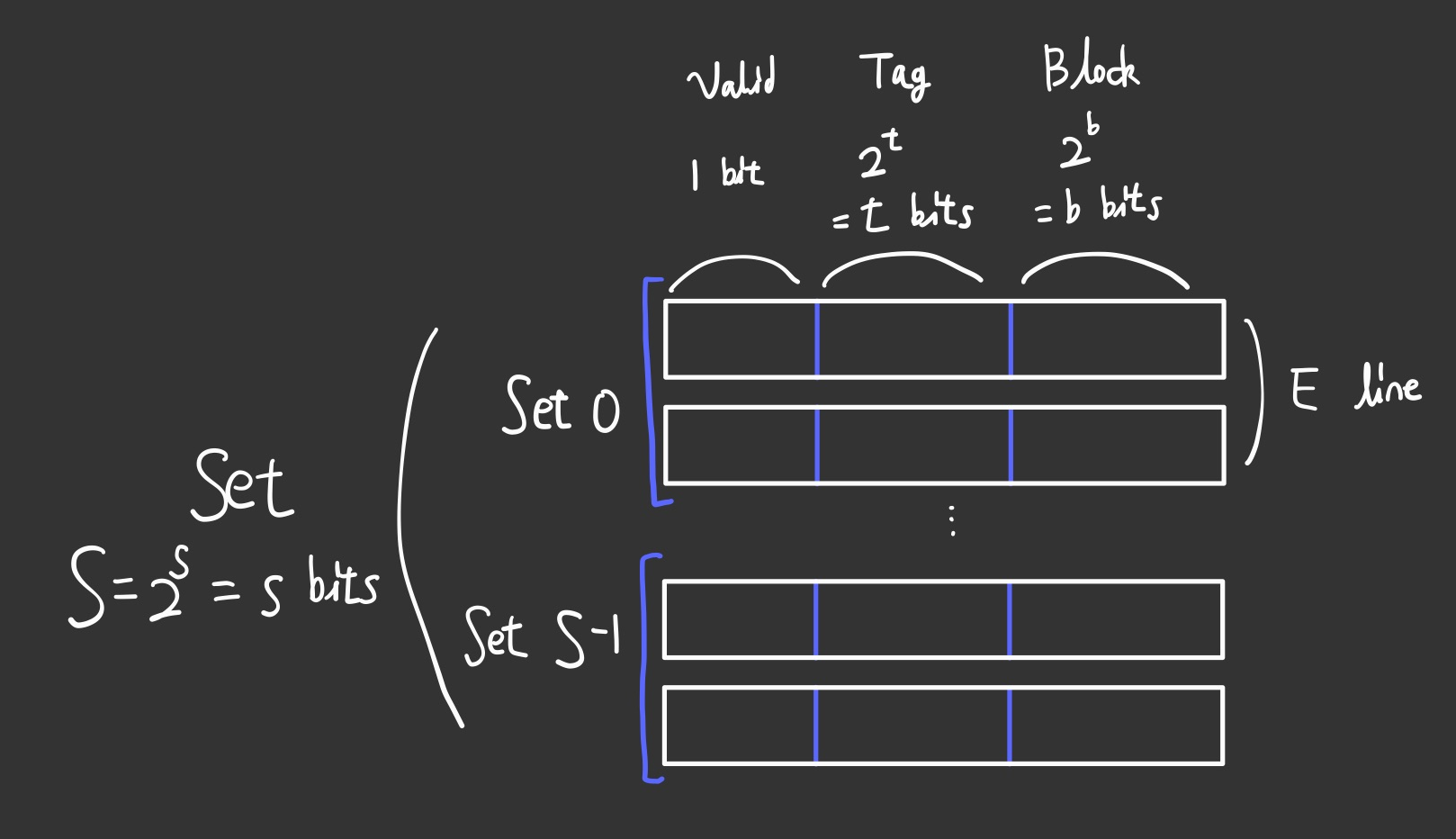
Cache는 위와 같은 구조로 되어있다고 보면 된다. 하얀 네모들이 모여서 Cache를 이룬다.
우선 각 공간을 Set으로 구분하는데, s 비트를 통해 2^s개의 Set으로 구분할 수 있다.
각 Set에는 E개의 line이 존재하며, 이는 비트가 아닌 특정한 값으로 각 Set마다 동일한 개수가 존재한다. 1개의 line만 존재하면 Direct-Mapped Cache이며, 2개 이상의 line이 존재하면 Set Associative Cache이다.
하나의 line은 Valid bit, Tag, Block 으로 나눌 수 있다. Valid bit는 boolean처럼 1개의 비트를 이용하여 해당 공간에 데이터가 적재되어 있는지 알 수 있다.
데이터가 존재한다면 Tag를 비교하며, 이는 t 비트를 통해 2^t개의 Tag가 존재할 수 있다.Tag까지 일치한다면 Block에서 데이터를 찾으면 되며, 하나의 Block에는 여러 데이터가 존재할 수 있다. 물론 특정 비트마다 구분이 되므로 데이터가 섞이는 불상사는 생기지 않는다.Set을 찾은 뒤에는 위에 서술한 과정을 각 line마다 순회하며 확인한다. 데이터를 찾는다면 Hit, 찾지 못할 경우 Miss이다.Miss이며 Valid하지 않은 line이 있다면 해당 위치에 새로 데이터와 이에 대한 정보를 넣는다.Miss이지만 전부 Valid하여 꽉 찰 경우, Cache 관리 정책에 따라 기존의 line 한 개를 교체한다.
가장 오래 전에 사용한 line을 교체하는 LRU (Least Recently Used), Hit 횟수가 가장 적은 line을 교체하는 LFU (Least Frequently Used) 등 많은 정책이 존재한다.
이는 OS에서 Paging에서도 동일한 기법으로 Page를 교체하기에 여러 정책들을 알아보는 과정이 필요하다.
데이터에 접근시 상단 레이어에서 Hit가 발생하면 더 이상 하단 레이어로 접근하지 않아도 되기에 속도가 빠르다.Miss 발생시 하단 레이어에서 데이터를 찾기 위해 동일한 작업을 반복하여, Memory Hierarchy에서 언급하였듯이 하단 레이어로 갈수록 속도가 느리기에 데이터 접근까지 더 긴 시간이 걸린다.Miss 발생을 줄이고 Hit 발생이 늘어날수록 프로그램 성능은 더 좋아진다. 이를 위하여 Locality에 대해 알아야 한다.
Locality
Locality란 프로그램이 특정 부분에 자주 접근하는 특성을 의미한다.
일반적으로 대부분의 프로그램은 모든 메모리에 골고루 접근하는 것이 아닌, 특정 부분에 훨씬 많이 접근하는 경향이 있다. 그렇기에 Locality를 신경써서 프로그램을 작성하는 것이 성능 향상에 도움이 된다.Locality는 두 가지로 나눌 수 있다. 시간적 지역성이라 불리는 Temporal Locality와 공간적 지역성이라 불리는 Spatial Locality가 존재한다.Temporal Locality는 특정 주소에 자주 접근하는 것을 의미한다. 일반적인 for loop에서 반복을 위해 변수 i를 쓰는데, 이 i가 바로 Temporal Locality에 해당한다.
같은 주소에 반복적으로 접근하기에 한 번 상단 레이어로 load되면 Hit가 발생할 가능성이 높다.Spatial Locality는 특정 주소 인근에 자주 접근하는 것을 의미한다. 배열은 연속적인 메모리들로 이루어져 있으며, 배열 전체를 탐색할 때 Spatial Locality에 해당한다.
같은 주소는 아니지만 가까운 위치에 있는 주소에 접근하기에 가까이 존재하는 데이터들을 상단 레이어로 load하여 전체적인 Hit 발생 횟수가 높아질 수 있다.
Matrix Multiplication
A 행렬과 B 행렬을 곱한 결과를 C 행렬에 집어넣는 행렬곱을 진행할 때, 보통 아래와 같은 방법으로 진행한다.
for ( i = 0 ; i < n ; ++i )
{
for ( j = 0 ; j < n ; ++j )
{
for ( k = 0 ; k < n ; ++k )
{
C [ i ] [ j ] += A [ i ] [ k ] + B [ k ] [ j ] ;
}
}
}많이 사용하는 방법이지만, Cache 관점에서 바라볼 때 이는 최선의 방법은 아니다.
서적에서는 i, j, k의 순서를 바꾸어 총 6개의 프로그램의 속도 차이를 보여주었다.
놀랍게도 가장 빠른 방법은 j는 마지막으로 고정시키고, i와 k가 앞에 나오는 프로그램이다.
for ( i = 0 ; i < n ; ++i )
{
for ( k = 0 ; k < n ; ++k )
{
iTemp = A [ i ] [ k ] ;
for ( j = 0 ; j < n ; ++j )
{
C [ i ] [ j ] += iTemp * B [ k ] [ j ] ;
}
}
}물론 Cache의 크기에 따라 다르겠지만, 각 Element는 double 타입이며 Block 크기는 32Bytes로 가정한다.
이 경우 iTemp에 저장하는 추가적인 연산이 생기지만, 전체적인 Miss가 줄어들어 성능이 훨씬 좋아진다.
| Order | Loads | Stores | A Miss | B Miss | C Miss | Total Miss |
|---|---|---|---|---|---|---|
| ijk & jik | 2 | 0 | 0.25 | 1.00 | 0.00 | 1.25 |
| jki & kji | 2 | 1 | 1.00 | 0.00 | 1.00 | 2.00 |
| kij & ikj | 2 | 1 | 0.00 | 0.25 | 0.25 | 0.50 |
각 `Iteration`별 `Miss` 횟수이다. 서적에서는 각 행렬의 크기에 따른 `Cycle` 그래프도 제공하였는데, `kij & ikj`는 크기에 무관하게 성능의 차이가 거의 없는 반면 나머지 방식의 경우 크기가 증가할수록 성능이 감소하는 것을 볼 수 있었다.
Cache Lab
https://github.com/kkanggu/bookclub-2022-csapp/tree/main/03-cachelabSet과 Block 비트, line 개수가 주어지며 이를 이용하여 LRU 방식의 Cache를 구현한다.
이 Cache를 이용하여 주어진 행렬을 Transpose하는 함수를 구현한다.Cache 구현인 csim.c 구현은 어렵지 않았다.
인자를 적절하게 처리하여 Set, Block의 비트와 line 개수, 테스트할 파일을 설정한다.
이에 따라 Cache의 개수를 계산하여 Set별로 분배한다.
명령의 경우 I, S, L, M 등이 들어오는데, I는 어떠한 명령인지는 모르나 Cache에 접근하는 것이 아니기에 무시한다.S는 save, L은 load, M은 modify이다. Save와 load는 Cache에 한 번만 접근한다.
Modify의 경우 Cache에서 데이터를 읽은 후, 다시 Cache에 접근하여 데이터를 저장하는 과정이다. 총 2번의 Cache 접근이 이루어진다.
각 Cache 접근시에는 Set, Block의 비트수를 이용하여 Set, Tag, Block 부분으로 나눈다.Set을 찾아가 Valid 확인 및 Tag 확인 처리를 하여 최종적으로 Hit, Miss, Evict 판정을 한다. 여기서 Evict는 Eviction을 줄인 것으로 Miss 후 빈 공간이 없어 교체되었다는 의미이다.Cache 구현은 아래와 같이 잘 이루어졌다.

좌측은 작성한 csim.c, 우측은 정상적인 구현시 Hit, Miss, Evict 횟수를 보여주어 프로그램에 문제가 있는지 알려주는 역할을 한다.Transpose를 담당하는 trans.c는 고민해야할 것이 많았다.
테스트는 총 3가지 행렬에 대해 진행하는데, 모든 행렬에 적용이 되도록 알고리즘을 작성할 경우 전체적인 성능이 좋지 않았다.
결국 각 행렬에 대해 맞춤형 알고리즘을 작성하였다.
32 x 32 행렬의 경우 8개씩 Transpose 작업을 해주었으며, 각 변수의 순서를 섞어 행렬의 앞에서부터 처리하는 것이 아닌, Cache를 염두에 두어 일정 간격으로 처리를 하게 되었다.
64 x 64 행렬의 경우 8개씩 처리했을 때 성능이 좋지 않았다. 각 변수를 조정하던 중 4개씩 처리를 하게 되었고, 이 경우 성능이 좋았다.
67 x 61 행렬은 나누어 진행하였다. 두 수 모두 소수이기에 이전의 2개처럼 편하게 작업을 할 수 없었다.
우선 64 x 60 행렬에 대한 Transpose 작업을 하였다. 이후 64 x 61로 만드는 작업을 한 뒤, 3 x 60을 먼저 처리한 후 나머지 3 x 1 처리를 해주어 67 x 61로 만들었다.
개별 성능은 아래와 같다.
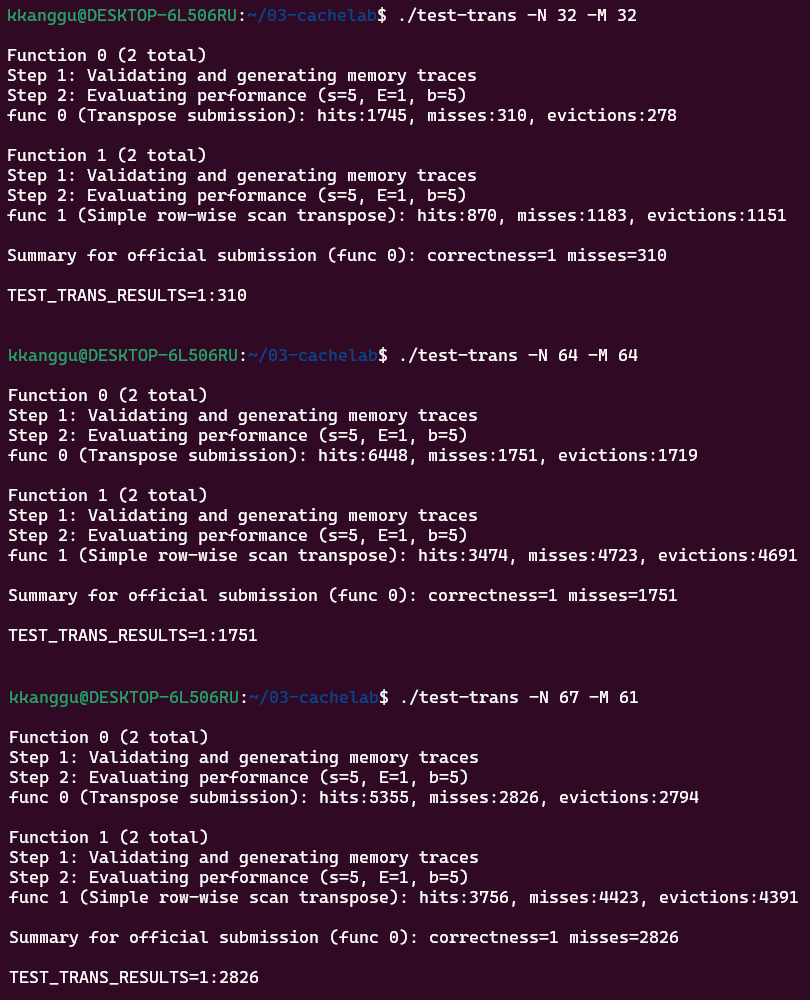
행렬은 설명한 순서대로이며, 각 행렬에서 상단이 작업한 trans.c를 이용한 Transpose 결과이며 하단은 가장 일반적인 Transpose 방식의 결과이다.
개별 결과를 보았을 때는 성능 개선을 꽤 하였다고 생각하였다.
최종적으로 제출한 프로그램의 결과는 다음과 같다.
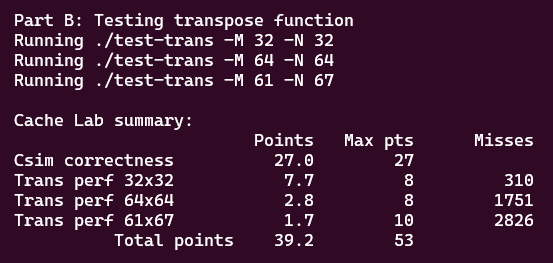
csim.c 구현은 정상적으로 잘 되어 모든 점수를 받았다.
다만 trans.c에서 32 x 32는 좋은 점수를 받았으나, 64 x 64와 67 x 61의 경우 끌어낼 수 있는 최대 성능이 훨씬 좋은지 점수를 거의 받지 못 하였다.
Conclusion
이번 챕터에서는 예상한 내용이 많았으나, 배워가는 것이 많은 챕터이다.Cache, RAM, Memory의 차이와 Hierarchy에 대해 확실하게 배울 수 있었다.Locality의 중요성을 다시 한 번 느낄 수 있었으며, 이를 신경쓰는 것이 좋은 성능을 가져온다는 것을 여러 예제를 통해서 알 수 있었다.cache lab 과제를 통해 Cache를 구현하여 동작을 다시 한 번 확인하였으며, Transpose의 구현을 통해 general한 방식의 단점과 specific한 방식의 단점을 모두 느낄 수 있었다.
'CSAPP' 카테고리의 다른 글
| CSAPP - Virtual Memory (0) | 2022.09.19 |
|---|---|
| CSAPP - Optimizing Program Performance (0) | 2022.08.11 |