title: HTTP The Definitive Guide - 05. Web Servers
date: 2022-11-10
tags:
- Network
- HTTP
Introduction

GDSC에서 해당 서적을 통해 HTTP를 공부하는 스터디에 참가하고 있다.
HTTP 이전의 내용은 개인적으로 공부하며 채울 예정이다.
이번 Chapter는 05장 Web Servers 이다.
Purpose
Web Server의 자세한 동작을 파악한다.
Web Server
Web Server라고 하는 것은 Web Server를 구성하는 장치와 이를 구현한 S/W 모두를 가리킨다.
Web Server가 제공하는 기능, 크기, 동작 등 매우 다양하지만 모든 Web Server는 HTTP Request를 처리하여 Response한다.
Implementation
Web Server는 HTTP와 TCP에 관련된 처리를 구현한다. Resource 관리, 관리 기능 제공, HTTP Protocol 구현 등 다양한 것들을 구현한다.
OS와 TCP 관리에 대한 책임을 나눠 갖는다. OS는 System과 관련된 H/W 관리, TCP/IP Newtork 지원, Filesystem을 이용한 Resource 관리, Process 관리 등 다양한 작업을 담당한다.
다목적 S/W를 설치하여 Web Server를 구현할 수도 있으며, 작은 칩에 적은 기능만 구현이 된 작은 Web Server를 구현할 수도 있다.
General-Purpose Web Server Market

서적에서는 2002년까지의 현황만 나와 있다. 당시에는 Apache가 압도적이었으며, 그 뒤를 MS가 따라오고 있었다.
어느새 MS는 찾아보기 매우 어려워졌으며, Apache의 점유율은 내려가고 nginx가 가장 높은 점유율을 가지게 되었다.
E

mbedded Web Server
Embedded Web Server는 작은 칩에 적은 기능만 구현이 된 작은 Web Server이다.
유저가 사용할 제품에 내장하기 위해 만들어졌으며, 프린터 혹은 가전제품 등에 사용된다.
A Minimal Perl Web Server
모든 기능을 가진 HTTP Server를 만들려면 매우 많은 Resource가 들어가며, Apache Web Server의 경우 중요한 부분만 50K Line 이상의 Code가 있다.
최소한의 기능으로 제한한다면 Perl을 이용하여 50 Line 미만으로 작은 Web Server를 구현할 수 있다.
서적에서는 Perl을 이용한 실제 Code가 있으며, HTTP Request를 출력한 후 Response에 넣을 데이터를 입력하여 Response하는 간단한 Web Server이다.
Real Web Servers
실제로 사용할 수 있는 Web Server는 위와 같은 최소한의 동작을 수행한다.
Step 1 : Set Up Connection
이미 Server와 Persistent Connection이 맺어져 있다면 해당 Connection을 사용하지만, 없다면 새로 Connection을 맺어야 한다.
Server에 TCP Connection을 요청하면 Server는 Client의 IP Address와 Hostname 등을 이용하여 상대방을 식별한 후 Connection을 맺는다.
Server는 언제든 Connection을 끊을 수 있으며, 일부 Server는 IP Address 혹은 Hostname가 인증되지 않거나 권한이 알맞지 않다는 이유로 Connection을 끊는다.
Server는 IP Address를 이용하여 Hostname을 가져오는 Reverse DNS를 이용하여 Client의 Hostname을 얻는다.
서적에서는 많은 Server가 이러한 방식을 이용한다고 하지만, 이 과정에서 발생하는 Overhead로 인하여 메일 Server를 제외하면 일반적으로는 Reverse DNS를 이용하지 않는다고 한다.
메일 Server는 스팸 메일을 필터링하는 데에 Reverse DNS를 이용하며, 등록된 Hostname이 없거나 Client의 Domain 정보와 DNS 결과의 Domain 정보가 다르면 스팸 메일로 인식한다.
Ident Protocol
일부 Server는 IETF Ident Protocol을 지원한다. 간단히 실제 Connection을 맺기 전에 Ident Connection을 맺어 Client의 이름을 알아내어 이를 Logging에 이용한다.
인트라넷과 같은 조직 내부에서는 사용할 수 있으나 Public Network에서는 여러 문제가 존재하기에 잘 사용하지 않는다.
- 많은 Client는 Ident Protocol을 지원하지 않는다.
- Ident Protocol로 인하여 지연이 발생한다.
- 많은 Firewall이 Ident를 허용하지 않는다.
- Ident Protocol은 쉽게 노출이 되기에 보안 문제가 있다.
- Virtual IP를 잘 지원하지 않는다.
Step 2 : Receiving Request Message
신호로 들어오는 Request를 Parsing하여 온전한 Message로 만드는 과정이다.
각 Line의 끝에는 CRLF가 있기에 이를 통해 Message를 만들 수 있다.

읽은 Message를 편하게 사용하기 위해 내부적으로 별도의 자료구조를 이용하여 저장한다.
위 사진은 하나의 예시이다.
Input/Output Architecture

Server에는 많은 Client가 연결되어 있으며, Connection을 효율적으로 관리하기 위한 Architecture가 필요하다.
- Single-Threaded I/O Architecture - 한 번에 하나의 Request만 처리하며, 처리가 끝나면 대기 중인 다음 Request를 처리한다. 또한 Request 처리 중에는 다른 Connection을 무시한다. 구현하기는 간단하지만 Traffic이 많아지면 성능 문제가 발생한다.
- Multiprocess and Multithreaded I/O Architecture - Multiprocessing 혹은 Multithreading을 이용하여 한 번에 N개의 Connection을 처리한다. 속도는 매우 빠르지만 Connection이 많아지면 너무 많은 Thread가 생성되어 Resource 과다 사용이나 성능 저하와 같은 문제로 이어질 수 있다. 그렇기에 해당 Architecture를 이용한다면 최대 Thread 개수 제한을 두어야 한다.
- Multiplexed I/O Architecture - 많은 Connection을 효율적으로 관리한다. Connection의 변화가 감지될 경우 처리를 하기에 Connection 관리에 용이하지만 하나의 Request만 처리하기에 Request가 많으면 Single-Threaded I/O Architeture와 비슷한 구조가 되어 성능 문제가 발생할 수 있다.
- Multiplexed, Multithreaded I/O Architecture - Multiplexed와 Multithreading을 섞은 Architecture이다. 간단히 Multiplexed I/O Architecture가 병렬로 존재하는 것이다.
Step 3 : Processing Requests
Request 동작을 처리한다. Method에 맞게 Header와 Body가 필요하며, 이 부분은 본 서적에서 계속하여 다루기에 여기서는 간단하게만 적는다.
Step 4 : Mapping and Accessing Resource
Server는 Resource를 모아놓은 후 필요한 Resource를 넘겨주거나 처리를 한다. 물론 어떤 Resource인지 올바르게 Mapping이 되어야 이러한 작업이 가능하다.
Resource Mapping에 다양한 방식이 존재하지만, 가장 간단한 것은 Filesystem을 이용하는 것이다.
Directory와 File로 구성하며, Server 내부의 어떠한 폴더를 Docroot (Document Root)로 지정하여 사용할 수 있다. 간단히 Linux의 Home Directory를 생각하면 된다.
Server는 하나의 컴퓨터이기에 제공하기 위한 Resource 외에도 내부적으로 System을 유지하기 위한 File과 Directory가 존재한다.
이러한 것들을 유저에게 노출해서는 안 되기에 Docroot를 지정하여 System을 안전하게 관리한다.www.google.com/../ 와 같은 접근을 생각할 수 있는데, 이러한 접근은 대부분의 Web Server가 막는다.
Virtual Hosted Docroot
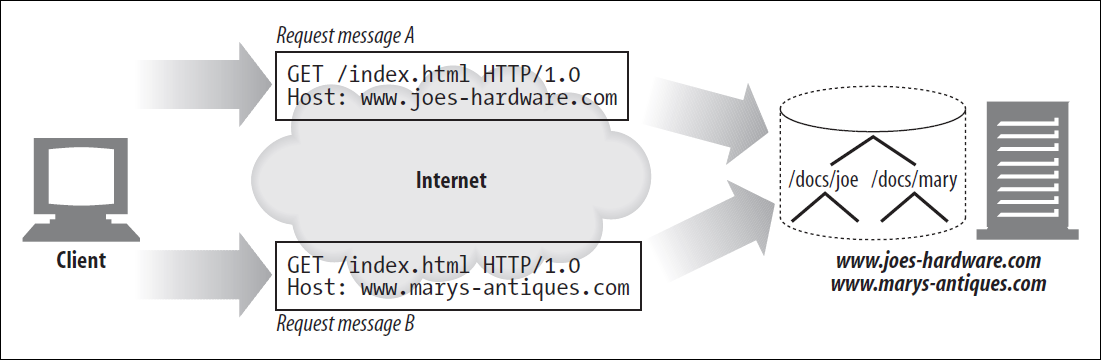
하나의 Server는 여러 IP Address와 Hostname을 가질 수 있다.
동일한 Server에 접근하는 것이지만, 여러 Site를 제공하여 Default로 넘겨주는 것이 다를 수 있다.
간단하게 특정 Site의 모바일 버전을 생각하면 좋을 것 같다. 동일한 Site를 보더라도 기기에 맞게 Site를 그려 편하게 사용할 수 있다.
물론 Virtual Host가 새로 생기기에 이에 맞게 Hostname, Docroot, Log 경로 등을 지정해주어야 한다.
Directory Listing
정확한 File이 아닌 특정 Directory만 Resource로 지정하는 경우가 있다.
이때는 에러로 처리, Default File로 대체, 해당 Directory의 HTML로 대체 등 다양한 방법으로 Resource를 제공할 수 있다.
일반적으로 index.html 혹은 index.htm을 Directory에 넣어두어 해당 File을 Default로 지정하는 편이다.
Apache에서는 DirectoryIndex라는 것을 두는데, Default로 제공할 수 있는 것들의 List를 만들어 이것 중 하나라도 존재하면 해당 Resource를 제공한다.
DirectoryIndex를 설정하였으나 어떠한 Default File도 찾을 수 없다면 해당 Directory의 HTML 파일, 각 파일의 크기와 수정 날짜, 각 파일의 URI를 제공한다.
이는 노출하고 싶지 않은 File들이 유저에게 노출되는 문제가 발생할 수 있으며, DirectoryIndex를 비활성화하여 이를 해결할 수 있다.
Dynamic Content Resource Mapping

Server는 동적으로 Resource를 제공할 수 있다.
Appliation Server라고 불리는 Server는 Backend Application을 연결해주는 작업을 한다.
Resource가 Dynamic Resource일 경우, Dynamic Content를 생성하는 프로그램의 위치와 어떻게 실행하는지를 알려줘야 한다.
대부분의 Server는 Dynamic Resource를 식별하고 Mapping하는 기본적인 절차가 존재한다.
Apache의 경우 /cgi-bin/으로 시작하는 URI의 경우 ... /cgi-programs/ 폴더에 있는 프로그램과 Mapping한다.
또한 .cgi File이 존재하며, 이는 간단하고 인기 있는 Server-Side Application을 실행하는 File이다.
Server-Side Include (SSI)
SSI는 Server의 다른 파일을 읽어서 삽입하는 방법이다. 코드 관리가 용이해진다.
많은 Server는 SSI도 지원하며, Response를 하기 전에 이를 Parsing하여 적절하게 처리한다.
변수 혹은 Embedded Script로 대체될 수 있는 특별한 패턴이 존재할 수 있으며, 이에 대한 처리도 지원한다.
이 방식을 통해 Dynamic Content를 쉽게 만들 수 있다.
Access Control
특정 Resource에 권한이 필요할 수 있다. IP Address로 지정할 수도 있으며, Password를 이용할 수도 있다.
자세한 HTTP Authentication은 Chapter 12에서 자세히 다룬다.
Step 5 : Building Response
Request에 대한 모든 처리가 끝나면 Client에게 Response한다.
Response Body가 존재한다면 MIME Type, 길이 등에 대한 정보를 Header에 포함하는 편이다.
MIME Type

Response Body에 대한 MIME Type을 지정해주어야 한다. 매우 간단하다고 생각할 수 있으나, 여러 방법이 존재한다.
- mime.types - Resource의 확장자를 이용하여 MIME Type Table과 비교한 후 MIME Type을 지정한다.
- Magic Typing - Resource의 패턴이 Magic Table과 일치하면 MIME Type을 지정할 수 있다. 성능은 좋지 않지만, 확장자가 없는 Resource에서는 유용하게 사용 가능하다.
- Explicit Typing - 확장자나 실제 내용과 무관하게 Server가 MIME Type을 지정한다.
- Type Negotiation - 다양한 MIME Type에 해당할 때, Client와의 협상을 통해 가장 적절한 MIME Type을 지정한다. 자세한 것은 Chapter 17에서 다룬다.
Redirection
Resource가 아닌 Redirection에 대한 Response를 3xx Status Code를 함께 보낼 수도 있다.
Redirection은 단순히 URL이 변경되었다는 뜻이 아닌, Server 입장에서 더 큰 이유가 존재할 수 있다.
- Permanently Moved Resource - 다른 위치로 옮겨지거나 이름이 바뀌었을 수 있다. 이때는 바뀐 URL을 Response하며, Client는 이를 확인하여 Bookmark를 갱신한다.
- Temporarily Moved Resource - 잠시 다른 위치로 옮겨지거나 이름이 바뀌었을 때 사용한다. 일시적으로 바뀌었기에 현재는 Response하는 URL을 이용하더라도, 추후에는 기존 URL을 사용해야 함을 알려준다.
- URL Augmentation - Embedded State 정보를 포함한 새로운 URL을 Response한다. Transaction간의 상태를 유지하기 위한 방식이라고 하는데, 정확한 것은 모르겠다.
- Load Balancing - 해당 Server의 부하가 크다면 여유가 있는 다른 Server로 Redirection하도록 유도한다.
- Server Affinity - 특정 유저에게는 다른 Server를 이용하도록 Redirection할 수 있다.
- Canonicalizing Directory Name - Trailing Slash가 빠져있을 경우, 이를 추가하여 Redirection하도록 유도한다.
- Trailing Slash - URL의 끝에 붙이는
/이다./가 있다면 Directory, 없다면 File을 지정하지만, Trailing Slash는 Host 직후에 나오는/를 의미한다.www.google.com의 경우/가 있어야 Docroot이며, 이를 내부적으로 처리하는 것이다.
- Trailing Slash - URL의 끝에 붙이는
Step 6 : Sending Responses
Response를 하는 것은 Request를 받는 과정과 유사하다.
Persistent Connection이 아니라면 데이터 전달 후 Connection을 끊으며, Persistent Connection이라면 계속 Connection을 유지한다.
Step 7 : Logging
Transaction이 완료되면 이에 대한 Log를 남긴다. 대부분의 Server는 Logging에 대한 설정 Form이 존재하며, 자세한 것은 Chapter 21에서 다룬다.
Conclusion
실제 Server의 동작을 상세하게 알아보았다.
Client 입장에서는 Request를 보내고 Response를 받기만 하면 되지만, Server는 많은 Client와 Connection을 맺기에 고려해야 할 점이 많다.
다만 이론적인 내용이기에 실제 Server를 구축하고 운영하는 경험이 필요할 것이다.
'Network' 카테고리의 다른 글
| HTTP The Definitive Guide - 07. Caching (0) | 2022.11.22 |
|---|---|
| HTTP The Definitive Guide - 06. Proxies (0) | 2022.11.18 |
| HTTP The Definitive Guide - 04. Connection Management (0) | 2022.11.07 |
| HTTP The Definitive Guide - 03. HTTP Messages (0) | 2022.11.04 |
| 성공과 실패를 결정하는 1%의 네트워크 원리 - 2. Data of TCP/IP to Electronic Signal (0) | 2022.10.25 |